
Quick, stable, self-contained: how we think about CI at Nerve
Right after college I spent two years at Microsoft, working on an internal pipeline that handled real-time telemetry data for Hotmail, OneDrive (SkyDrive back then), and some other major services. All told it was a great job; I got to hang out in Seattle and learn from some very smart and kind people.
On the other hand, our CI took eight hours.
To be fair this was all the way back in 2012 (a year before Docker and two years before Kubernetes), and we were using cutting-edge approaches for the time. On checkin we would run our acceptance test suite, which meant provisioning an entirely fresh deployment. To do this we would check out a bunch of VMs from a VM pool, completely re-image them with a new OS (no containers back then!), and deploy the appropriate applications on each host, which included things like installing SQL Server on our backends. Then we would run a lot of automated integration tests, which often involved waiting around for the pipeline to ingest enough data.
I don't think any one person or decision was to blame for these slow builds (and I'm not even sure it was possible to make them faster at the time), but the fact was that they were slow, and I personally found that to be a huge drain on my energy and motivation. When I landed a feature, I knew for a fact that CI wouldn't be done before I left for the day; if there were multiple rounds of test failures (or, even worse, if some of the tests ended up flaking), it could take most of the week just to check something into the production branch. I often found it very hard to keep a sense of momentum going when it could be such a struggle to actually get my code in the product. This was particularly demoralizing if I was coming up on a deadline; I'd land my changes and wait for hours with a mixture of boredom and dread, hoping against hope that the green tests in my local environment would stay green in CI so I could ship on time. I had a lot of takeaways from my years at Microsoft, and among them was a conviction that fast, stable infrastructure is non-negotiable if you want happy developers at your organization.
Now, more than a decade later, I'm starting a company of my own, so I have a chance to create the kind of build process I pined for back in 2012. This write-up describes how I designed CI at Nerve, the tradeoffs I made along the way, and the directions I'd like to explore in the future.
CI at Nerve typically takes somewhere between three and three and a half minutes to run (deploys are triggered separately and add about another minute):
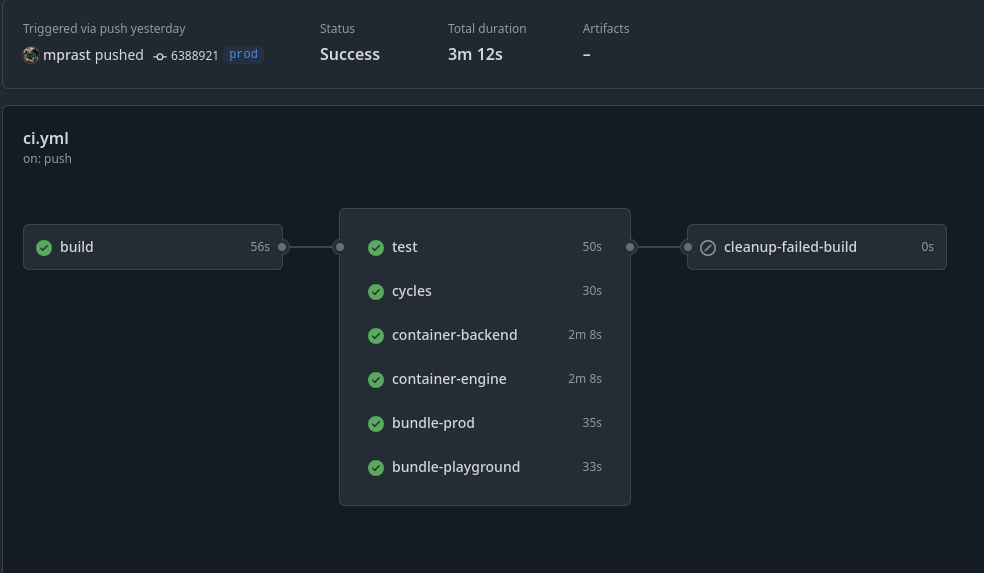
Each build typechecks, transpiles, tests, and packages all of the code contained in the Nerve monorepo. In total, Nerve consists of about three hundred thousand lines of code, not including dependencies. So, not huge, but not small.
A quick note before diving in: so far Nerve is a solo project. It felt very strange to write this whole post in the first person singular, so you'll sometimes hear me talk about things "we" do at Nerve. For now it's just me, though.
Before we go on I need to tell you a bit about what Nerve is and how it's architected, or some of the stuff I talk about later isn't going to make sense.
Nerve is a universal SDK. If you're using an API that doesn't have an SDK (or if you don't like the SDK it does have) you can use Nerve to query it instead of rolling your own client.
Nerve consists of:
- a webapp that keeps track of API configuration info and has a browser-based query builder.
- a query engine called the Nerve Engine that actually runs the queries you write.
1. is the control plane and 2. is the execution plane. Here's an architecture diagram that roughly shows how the pieces fit together:

Throughout the rest of this article I'll be referring to the three main "components" of Nerve. These are: the frontend of the webapp (which is an SPA), the backend of the webapp, and the Nerve Engine. All three components are written completely in Typescript.
Design goals
Fast builds are important, but speed is just one dimension of many. A fast pipeline that is overly brittle, complex, or difficult to manage probably won't stay fast for long.
We have a couple specific design principles we tried to adhere to when designing our build process (these are in addition to the implied values of Fast, Lightweight, etc. - those go without saying.) These apply not only to CI, but to all of the infrastructure we're building at Nerve.
No "special" code
To the greatest extent possible, we want to centralize the code we write at Nerve and have a simple, standard way of writing/tracking/building/executing it (another way to put this is that we adhere to a Google-style monorepo philosophy, although of course we are at a microscopic scale compared to Google.) We don't want there to be a notion of "auxiliary" code that's stored in a different place and is edited or reviewed or checked in differently. Our build scripts are all contained in the same monorepo that hosts our product code.
Locally reproducible
In my opinion, nothing helps with debugging more than being able to run a process locally. Once you've got a local copy it's easy to inspect source systems, attach a debugger, mess with stuff and see what happens, and so on (I find this also helps when developing new stuff.) At Nerve we try to ensure that every part of our product and infrastructure is runnable locally with minimal hassle. Our build scripts are no exception - after replacing some env variables a developer can run any of our build steps on their local machine (to make this happen we had to make sure that our scripts didn't depend on vendor-specific functionality from our build runner, Github Actions.)
Accessible to others
We have a general policy of fostering curiosity, which means it should be as easy as possible for people to learn about parts of the codebase that may not be directly related to their job. In line with this, we aimed to make our build system accessible to "normal" engineers, and not just infrastructure specialists. This meant biasing towards simple and mainstream tools and techniques when we didn't have a compelling reason to get fancy.
Minimal artifacts
It's important that our build process is fast, but we want the result to be fast too! Some of this depends on the code itself, of course, so we can't control it at build time, but one dimension we can have an effect on is the size of our artifacts. Bundle size is famously important for frontend loading times, but it's also nice to keep our backend containers as small as possible - this makes it easier to move new versions of the backend around, speeding up production deploys and making it faster to, for example, deploy a particular branch or commit to your local machine.
Preserves the "Center of Gravity"
We don't want the build process (or any other infrastructure) to mess with the "Center of Gravity" of our other teams. In other words, product developers (of course when I say "product developers" I mean me when I'm working on the product) shouldn't need to write their code in a special way or do any other special rituals to make sure things work with the build pipeline. In other other words, product developers shouldn't need to think about the build process at all up until the exact point when they submit a PR.
The repo architecture
As mentioned, Nerve is a monorepo. It's a homogenous monorepo, to boot - everything is Typescript and our entire toolchain is Typescript-based.
At the root level are various config files and helper scripts, along with things like docs and our Kubernetes config. It also contains a top-level package.json which specifies tools and packages that all the code at Nerve depends on (for example, this is where we declare our dependency on Typescript. We run tsc exclusively via yarn tsc to ensure we're always running the same version.)
The meat of the codebase sits in the packages directory. This is a flat directory of over a hundred first-party Typescript packages, all of which have basically the same structure:
packages/
├── tsconfig-base.json
├── nerve-backend/
│ ├── jasmine.json
│ ├── package.json
│ ├── tsconfig.json
│ ├── bin/
│ │ └── bootstrap.js
│ ├── src/
│ │ ├── index.ts
│ │ ├── ...
│ │ └── test/
│ │ ├── backendTest.test.ts
│ │ └── ...
│ └── lib/
│ ├── index.js
│ ├── index.d.ts
│ ├── ...
│ └── test/
│ ├── backendTest.test.js
│ ├── backendTest.test.d.ts
│ └── ...
├── nerve-frontend/
│ └── ...
├── nerve-engine/
│ └── ...
├── component-library/
│ └── ...
├── type-utils/
│ └── ...
├── model-utils/
│ └── ...
└── ...That tsconfig-base.json at the top level contains the default settings we want to use for all of the packages; this includes things like the compilation target as well as various style-specific flags such as strictNullChecks, noImplicitReturns, and noImplicitAny. Each package has a tsconfig.json that inherits from tsconfig-base.json. There's also a tsconfig.json at the top level of the repo that simply contains a project reference to every package. The upshot of all of this is that you can run tsc on the entire Nerve monorepo by doing yarn run tsc -b . from the repo root, and you can run it on a particular package (and its dependencies) by doing yarn run tsc -b packages/<packageName> from the repo root.
Even though the packages/ directory is flat, the packages inside it depend on each other in various ways. There are three major "roots" of the package graph, each corresponding to a component of Nerve - nerve-frontend, nerve-backend, and nerve-engine. nerve-backend and nerve-engine are runnable packages, so they can be started by cd-ing to the repo root and running yarn run nerve-backend or yarn run nerve-engine (although you'll need to set some appropriate env variables to get them to actually start without crashing.) nerve-frontend is not runnable (by Node), but it contains some esbuild config that describes how to bundle it and its dependencies. The entry point for the bundle is nerve-frontend/lib/index.js. The different components of Nerve share a lot of common framework code, so their package graphs are pretty intertwined.
Each package has its own package.json that contains its dependencies. These can be third-party dependencies (e.g. left-pad) as well as references to the other first-party packages in packages/. To add a (third-party or first-party) dependency to a package, developers can navigate to the package root and just do yarn add <packageName>. To add a dev dependency for the entire repo, developers can navigate to the repo root and do yarn add <packageName>.
There are various runners at the top level of the repo. These are simple Javascript files that make it a little easier to run some utilities on the monorepo. The ones relevant to this post are esbuild_runner.js and jasmine_runner.js. These are wired into package.json via the scripts field like so:
scripts: {
jasmine: node jasmine_runner.js,
jasmined: node --inspect jasmine_runner.js,
esbuild: node esbuild_runner.js,
...
}
To (re)build the frontend bundle, you can do yarn esbuild <dev|prod> from the repo root. To run jasmine, you can do - you guessed it - yarn jasmine from the repo root, and to run jasmine on a particular package you can do yarn jasmine <packageName> from the repo root.
Now we'll go over all of the different parts of our CI flow. Each of these has its own "mini-script" that is referenced in the top-level YAML file that defines our workflow. We use Github Actions for CI, and DigitalOcean (which I'll abbreviate to DO) as our cloud provider.
One important way we make our CI faster is to optimistically generate and upload build artifacts while tests are running. If any tests fail (or if anything else goes wrong), we run a cleanup step that removes the artifacts from where they're stored in DO Spaces (the DigitalOcean equivalent of S3) and the DO Container Registry.
The build
Before we can run tests, build containers, or do anything else, we need to a) turn our Typescript files into Javascript files and b) typecheck and immediately fail the build if we find any errors. As mentioned, this is just a matter of running yarn tsc -b ., but we're currently on an older version of the compiler, so building Nerve from scratch takes several minutes.
You might have been wondering what that -b does. It's a way to tell Typescript to run in "build mode" (I know that's a little redundant but bear with me.) Build mode is a way to tell tsc to build a graph of projects that all depend on each other (in Nerve every package is also a tsc project.) Importantly for our purposes, tsc will only rebuild packages that have changed, along with their dependents. Essentially -b tells Typescript to do an incremental build, which is almost always much faster than building everything from scratch.
Ideally we'd like every build in CI to be an incremental build, but that means we need something to build on top of. We need to find a way to "hydrate" the repo with the latest successful build; then tsc will only recompile the packages that have changed in the interim.
Hydrator
I wrote a simple utility that can pull a build down from a DO Spaces bucket and move it into a local copy of the monorepo, and vice-versa. When I say "build" I mean a tarball containing the contents of lib/ for every single package - this includes transpiled Javascript files as well as type declarations (.d.ts files.)
hydrator stash <commitID> will move the appropriate files out of the monorepo into a staging directory, tar the staging directory, and upload the result to the nerve-builds bucket under a key that contains the given commitID. Meanwhile, hydrator load makes a call to git rev-parse to get the the SHA corresponding to HEAD, then looks in nerve-builds for a build corresponding to that SHA. If it can't find one, it goes backwards though the git log, downloading the first build it can find and moving it into the monorepo (it gives up after looking at 100 commits.)
This behavior is nice because it means we don't have to store a build for every commit: if, for example, typechecking or testing failed for a commit, there's no reason to upload a build. It also means we don't have to do any surgery if there's a problem with the build pipeline that prevents hydrator from running correctly.
It's significant that hydrator moves the build files into and out of place, rather than copying them. Moving a file just updates an entry in the file table, so it happens pretty much instantaneously. Meanwhile, copying a file involves rewriting the whole thing to disk, which takes longer.Bootstrapping
hydrator needs to be runnable before we pull a build. To keep things consistent we'd like to be able to write hydrator in Typescript, but we need to be able to run it without needing to run tsc or yarn first (we'll see why we can't run it with yarn in the next section.)
hydrator is the only package in Nerve which has its lib files (i.e. its transpiled Javascript files) checked in. We also install its dependencies with npm instead of yarn, and we keep the dependencies inside of a node_modules folder within the package. This node_modules folder is also checked in. What all this means is that whenever you clone a fresh copy of the Nerve monorepo, you can immediately run node hydrator/bin/bootstrap.js load to hydrate your repo with the appropriate build, with no extra setup steps. As we'll see later, this can be quite handy!
Security
It's very important that we ensure the code we check in is the code that actually gets deployed; if hydrator simply downloads and installs builds sight unseen, that means that anyone with our DO Spaces key could silently inject malicious code into the build and get it to run on our servers (or worse, our customers' servers.) We need hydrator to sign the builds it uploads and verify signatures on the builds it downloads to make sure no one can get away with doing anything nefarious in between.
Caveats & alternatives
I have a confession - this section is going to be mostly obsolete when tsc 7 comes out. The Typescript team is rewriting tsc in Go, and once they're done I'm pretty sure I'll be able to build Nerve from scratch in a couple of seconds. It's still nice to have hydrator around, especially since it means I don't have to suffer through slow builds until I can find time to upgrade Typescript. Once I'm able to move over though, I can simply run tsc to build the whole codebase every time and throw a lot of the other infrastructure away.
I could, of course, also speed up tsc dramatically right now by just using it as a transpiler, but I'd really like to do typechecking in CI. In my opinion, catching errors via the type system is always preferable to having to unwind downstream test failures or runtime errors. I don't really see skipping typechecking as a viable option.
For the same reason, I'm ambivalent about using ts-node or tsx. I'm loath to introduce another layer of indirection at runtime, but even if I wasn't, I'd need to have a typechecking step at the beginning of CI no matter what - even if it didn't do any transpiling - just to make sure I catch any potential type errors.
The only reason I can think of for using ts-node is that none of the other steps would be blocked on transpilation if ts-node could do it just-in-time. Before I knew about tsc 7 I probably would have explored this option more, but now I'm not sure it's worth it.
One other minor note - most CI runners offer artifact caches that will persist builds across different steps in a pipeline, or even across different pipelines. I thought about using one of these, but hydrator was not hard to write, avoids vendor lock-in, and works outside of CI. It fits my needs for now, and by the time I outgrow it I'll probably be on tsc 7.
The dependencies
We're using Yarn to manage all of our dependencies (if you'd like an overview of how Yarn works, I wrote about it in an earlier post - check out the third section, aptly titled "Yarn". Note that Yarn has now progressed past v2 and is now at v4.) In particular we're using the workspaces feature, which is nice because it means we can install all the dependencies for every part of Nerve just by running yarn install from the root of our monorepo.
Just like tsc build, a successful yarn install is a prerequisite to running everything else in CI (in fact, since we include Typescript itself as a dependency in our top-level package.json, yarn needs to happen before tsc.)
yarn is bottlenecked on a lot of network requests, not on the CPU. Anything involving the network is going to be affected by lots of factors that are hard to control, from both a reliability and a performance standpoint - ergo, caching dependencies in a single place arguably adds even more value than caching builds (lest you think me a firebrand for suggesting this, I'd like to point out that the yarn docs advocate for basically the same thing; the difference is that the docs advocate for checking cached dependencies into the git repo, and I'd prefer to keep them out, mostly because I don't think there's an especially good reason for them to be in there (I consider yarn.lock to be the source of truth for dependencies, and yarn.lock is already checked in.))
The obvious move here is to tarball and store npm_modules using hydrator. yarn doesn't actually use npm_modules, it uses its own cache directory (again, see here for how and why), so we can just cache that instead. All we did to make that happen was change how hydrator works, so now node hydrator/bin/bootstrap.js --force stash $GITHUB_SHA also tars and uploads $REPO_ROOT/.yarn/berry/cache.
We update the yarn cache during the build job. Right before running tsc -b ., we do yarn install to pull down whatever packages weren't cached by the last run. The time this takes depends on the number of new packages, of course, but in general a yarn install with cached dependencies takes around eight seconds (most of this time is spent regenerating the .pnp.cjs file that yarn uses to load dependencies at runtime.) Currently, a fresh yarn install from scratch takes about a hundred seconds.
init-job.sh
hydrator is our bootstrapper; a single hydrator run gets us to the point where we can run arbitrary Typescript code in the monorepo. We make the necessary calls in a (very simple) script called init-job.sh that runs at the start of every CI job (we also run yarn install really quick to make sure yarn is appropriately initialized with the newly-pulled package cache. When I said hydrator bootstraps us completely I fibbed a little.)
# init-job.sh
node hydrator/bin/bootstrap.js --force load
yarn install
This takes anywhere from ten to twenty seconds, depending on the network latency.
Security
You may be wondering if caching dependencies like this suffers from the same vulnerabilities that caching builds does - if a bad actor got the appropriate Spaces keys, couldn't they poison the supply chain by swapping in a tainted version of some deeply-nested dependency?
Luckily, no. yarn keeps a checksum of every installed packages in yarn.lock. When yarn loads a package from the cache, that package must be exactly the same as it was when it was originally installed. Packages are installed by individual developers in their development environments, and when they're installed the first time they're pulled from npm. Since all public npm packages are signed to prevent tampering, it's a pretty safe bet that the packages will be legit the first time you pull them (unless someone manages to impersonate the package author and publish a new version, but that's another story.)
All of this combined means we don't need to sign the package cache like we do the build cache; if something is amiss with a package yarn will ignore it or blow up.
Caveats & alternatives
One obvious alternative to the kind of caching we're doing is to use a mirror repository to host our packages. The idea is to have our own private package repository that basically acts as a read-through cache; if we want to pull a package, we first look in the private repo; if it's there, we pull it, if not, we pull it from npm and cache it in the private repo, so it'll be there the next time we need to use it. To get the kind of speedup we want, the private repo would need to be a lot speedier than npm - ideally it'd be located as close as possible to the in place we do CI.
In some ways having a read-through cache feels to me like the "right" way to handle dependencies; it would certainly be convenient and minimally invasive. However:
- Currently available internal package repositories (e.g. Github/Gitlab Packages) don't appear to be built with this read-through use case in mind; they seem to mostly be focused on hosting internal/first-party packages, not third-party dependencies. I'm sure I could make it work, but it'd probably take some glue code and elbow grease; nothing appears to be suitable out-of-the-box.
On the other hand, there's an OSS package registry called Verdaccio which has a great uplinks feature that's exactly what I want, but I'd need to host it myself. I'm not looking to manage another service, especially not one that will block CI if it goes down. I like the idea of just pointingyarnat something like UNPKG to help speed up fetch times, but as far as I understand it that service is kept up on a best-effort basis, so probably not a good idea to use it for something mission-critical. - Less importantly, I'm not 100% certain that fetching thousands of individual tarballs from the mirror will be as fast as downloading a single big file. My gut tells me that it would be about the same, but I haven't actually measured it, and in light of the other issues above I won't probably get around to it for a while.
The realpolitik bottom line is: I'm treating the whole cache as a unit because it's simply easier (it's easier for me at least, and for better or for worse that's the criterion right now, since this is a one-person team.) This, of course, is liable to change as things move around in the future!
(EDIT: Since writing this I have learned that CodeArtifact can function as a package mirror so I'll maybe use that...maybe. It's an AWS Service without a DigitalOcean equivalent, so for now I'll keep it in mind for if and when I need to move cloud providers.)
You may also have noticed that while I described a mechanism for adding packages to a cache (yarn install), I didn't describe one for removing them. It would be nice if yarn install cleaned up unused packages from the cache when it ran, but it seems like it doesn't (although this behavior currently seems to be undocumented so I could be wrong.) This means that if we remove a package in development, it won't be removed from the package cache we persist to DO Spaces, which means the cache we use for CI will get larger and larger until it potentially causes a problem. This isn't the end of the world - it just means that we need to periodically wipe it away and replace it with a cache produced by a completely fresh yarn install. More on this later!
The tests
Our testing philosophy
The way we write tests is influenced by the way we write all of our other code. Nerve's specific architecture could fill another blog post (or five), but one of its core tenets is the strict and universal separation of pure, stateless business logic from stateful adapters, in the spirit of the hexagonal architecture or Gary Bernhardt's "Boundaries" talk. This means that from a unit-testing standpoint, the "stuff we care about" (the first-party logic that we wrote ourselves) is always contained in a pure function. Testing a pure function is quite straightforward - you provide certain inputs, and verify that you get back what you expect. There's no database or other infrastructure to set up, and no mocking to configure (I'm being literal here - I don't have a favorite Typescript mocking library because I don't know what they are.) All of our unit tests are tests of pure functions, which keeps them fast, reliable, and easy to write.
Nerve has a bit over 600 unit tests, which are largely clustered around the backend and the Nerve Engine. Frontend bugs are not good and we'd like to prevent them, of course, but they mostly affect the usability of the webapp (i.e. the control plane.) A query engine that returns subtly wrong results, on the other hand, is DEFCON 1. The Nerve Engine affects not only the performance of our customers' applications, but their correctness too, which is why we have put the bulk of our testing efforts so far towards making sure the Engine is rock solid.
As we fill out our test coverage (which is a priority) we'll focus on keeping our build fast via aggressive test parallelization. Another advantage of testing pure functions is that the tests are very easy to run in parallel.
Intra-Process Integration Tests
We've covered unit tests, but we also need integration tests to ensure that our different units come together as a working system. As is typical, we need to test workflows that span multiple different components that may be running on different hosts. This is where we do something a little tricky - something that's only possible because a) every component at Nerve is written in Typescript and b) our codebase is mostly comprised of pure functions.
Whenever possible, we write our integration tests as stateless tests that run within a single process. I like to call this pattern Intra-Process Integration Testing (or IPIT, for short. I thought about calling it Single-Process Integration Testing, or SPIT, but decided that was a little gross.) Intra-Process Integration Tests don't require any extra infrastructure, and usually involve testing a sequence of pure functions (in fact, most of our integration tests end up looking like exceptionally large and complicated unit tests.)
As an example, let's take a look at a very core flow in Nerve - the query flow. If you'll forgive me for dropping in this architecture diagram again:
The query flow centers around steps one, two, five, and six. We want to ensure that Nerve can plan and execute a given query in a given environment and return the correct results every time. This flow involves every component of Nerve - the frontend (which constructs an object representing the user's query), the backend (which plans the query), the engine (which executes the query), and some APIs (which the engine pulls data from.)
The specific way we construct the integration tests for this flow are out of scope for this article, but here's some very simplified pseudo code representing the general structure of each test:
// dumpQueryStringIntoObjectModel is imported from the frontend.
// for each test, queryString is a different test fixture
const query = dumpQueryStringIntoObjectModel(queryString)
// planQuery is imported from the backend. apiContext contains
// a lot of information about available APIs that the query
// planner needs to construct a plan. In the integration
// tests, all of these "APIs" are hardcoded fixtures,
// and apiContext is hardcoded as well
const queryPlan = await planQuery(query, apiContext)
// executeQuery is imported from the engine
const results = await executeQuery(queryPlan)You may be wondering how we mock out the APIs that executeQuery() calls, especially when I explicitly mentioned we don't use any mocking libraries at Nerve. Well...that's a topic for a future post.
For the query execution flow, we have thirty-eight integration tests that simulate scenarios of varying sophistication. On my machine (a two year old ThinkPad) it takes about eleven seconds to run them all in sequence using jasmine. As mentioned, all of these tests run entirely in-memory, in a single process.
It's reasonable to point out here that the pathway we're testing is not the exact pathway that the data takes in production. In production, the query plan is stored in a database after it's created, and there's a network boundary dividing the query builder and the query planner, as well as the query planner and the query executor. What doesn't change is the data itself and the functions that operate on that data. The functions we import and call in the tests are the same ones that are called in production. The generated query plan is exactly the same in the tests as it would be in production, and the query executor runs it in the same way - it just returns the results directly from the function call instead of sending them back over the wire.
We achieve confidence in our integration tests by making sure the 'connective tissue' between different components is extraordinarily simple. At the risk of sounding like a broken record: we do this by pushing as much logic as we can into pure functions.
Running the full test suite is very simple: we just do yarn jasmine. This will run all of our unit and integration tests. On my machine running everything takes fifteen seconds. On the Github Actions runner it takes about twenty five. Since we can run tests with a single command, there's no test.sh script - we just inline the test command into the workflow.
Caveats & alternatives
The alternative strategy here is straightforward: run each test completely end-to-end, using various mechanisms to test the stateful parts at the boundary (things like setting up a test database for unit tests in Rails and full browser-based testing with Selenium.) We feel that these approaches would make our tests substantially heavier and more obtrusive without commensurate benefit, and prefer instead to drive down risk by making our stateful machinery as simple as possible. We also acknowledge that other teams might feel differently; ultimately the correct strategy depends on the business requirements, the technologies used, and the preferences and temperament of the team.
The packaging
We produce one artifact for each component of Nerve - a bundle for nerve-frontend and a container for each of nerve-backend and nerve-engine. Our customers run the engine container, and we run the backend container.
The bundle
Luckily there isn't a lot we need to do ourselves when it comes to the bundle. We can get great performance just by using esbuild instead of webpack, and we also get tree-shaking and minification out of the box, which helps keep our bundle as small as possible.
Speaking of - our total bundle size, gzipped and minified, is ~400kb. The frontend is a thick client that does a lot beyond CRUD, so this isn't terrible, but it could be better. That said (and I know I'm contradicting what I said earlier about minimal artifacts), Nerve is a tool for developers that is only supported on desktop, and the bundle is also going to be cached most of the time, so the bundle size - which does eventually need to be brought down! - is probably not going to be at the top of the priority list for a while. When we're ready to focus on it, we'll probably start with code splitting (the bundle currently isn't split at all.)
To bundle our frontend we run this simple script (we have a demo environment we refer to as the "Playground" and we make a separate bundle for it):
# bundle.sh
DEMO_ON=$FOR_PLAYGROUND yarn run esbuild prod --nowatch
tar -cvf assets.tgz packages/nerve-frontend/assets/*
yarn run spaces-cli up assets.tgz -t /frontend-assets/$FRONTEND_ENV/$GITHUB_SHA -s nerve-builds -r nyc3 -i <redacted> -k $DO_SPACES_SECRETThis runs in about ten seconds.
The containers
The naive strategy here is very simple - copy the whole repo into the container and make the entrypoint yarn run <nerve-backend|nerve-engine>. However, that would embed Nerve's entire codebase into each container, making the resulting images much bigger than they need to be. Our backend image size affects how quickly we can deploy new code, and our engine image size affects how quickly our customers can deploy, so we feel that it's worth it to try and save as much space as we can.
Let's approach this from first principles. nerve-engine and nerve-backend are both Typescript packages. If we were a third party, the way we would expect to consume them is by simply doing yarn install nerve-engine or yarn install nerve-backend. yarn would install the package we wanted along with its dependencies, and nothing else. Quick, easy, minimal. We should build our containers this way!
To be clear, our goal is to take the git repo out of the equation entirely. We essentially want to run yarn install <nerve-backend|nerve-engine> in a completely empty container and end up with something we can run. In order to make this work, we need to make sure yarn can pick up the appropriate first-party and third-party packages. To pick up first-party packages, we have to "publish" them to some "repository" that yarn can pick up.
Why the scare quotes, you ask? Can't we just use the npm registry in the obvious fashion? Technically yes - but there's a catch. We'd need to publish all of our packages privately, which is possible in npm using scoped packages, but all references to those packages would have to include their scope. This means every import would need to look like, for example, import {x} from @nerve/model-utils;
To be blunt, this is annoying, and it clashes with the way yarn handles inter-workspace dependencies (you can reference other workspaces just using their name - like you'd reference any other package.) Using npm means we'd need to follow a specific naming convention everywhere just because of the strategy we're using to do our builds. In other words, it throws off our center of gravity - specifics of the build process would be bleeding over into the way the product is architected. We really want to avoid this.
Luckily there's another option. You may remember verdaccio from earlier in this post - although we'd rather not use it as a mirror registry, it's perfect for this use case, where we just need an ephemeral local registry that can go away at the end of the container build. Now we can just spin up verdaccio, publish all of our packages to it as public packages (since we're not allowing any connections to verdaccio from anything but localhost), and tell yarn to pull from it instead of npm.
Now for third-party packages. We already have the package cache available via hydrator, and we should pull from it instead of slowing down the build by pulling over the network. Of course, it's not good enough to simply copy the package cache into the container - that still makes our container way bigger than it should be. What we want is to for yarn to use the cache almost like an upstream registry as it installs packages into the container...
Our streak of good fortunate continues, because yarn has a feature that does exactly that. The yarn docs refer to it as using an "offline mirror"; it's a feature that's intended to be used with multiple Typescript projects at once. When it's turned on, yarn will use two caches - one "global" cache that holds the packages for every project, and one "local" cache that only holds packages for the project yarn is run inside of. When yarn needs a package, it first looks to see if it exists in the local cache; if it doesn't, it looks to see if it exists in the global cache, and it copies the package from the global cache to the local one. If the package also doesn't exist in the global cache, it goes ahead and pulls it from the remote repo.
Now we have a simple process to create a minimal container build for any runnable package in our repository:
- We stand up a local
verdaccioserver to keep track of our first-party packages. - We publish each package in
packages/toverdaccio. - We copy the global package cache into the container.
- We tell
yarnto look atverdacciofor packages instead ofnpm. - We create a
package.jsonthat only contains our target package by doingyarn add <packageName>. - We run
yarn install.yarnattempts to pull our target package and all of its dependencies. When it needs a first-party package, it looks in the local cache (where it doesn't find it), looks in the global cache (where it doesn't find it), then looks inverdaccio(where it does find it.) When it needs a third-party package, it looks in the local cache (where it doesn't find it), then looks in the global cache (where it does find it.) In both cases it copies the relevant package into the local cache. - We remove the global cache from the container.
- we set the entrypoint to
yarn run <packageName>. When we run the container,yarnpicks uppackageNamefrom the local cache and runs it. - We tear down
verdaccioand push the newly built container to the DO Container Repository.
(Before we do the install we need to be sure to copy yarn.lock into our container, so that the package versions we end up installing into the container are all exactly the same as they are in development.)
All of our containers use Alpine Linux as the base image (which is pretty standard practice.) Alpine Linux is tiny so this helps keep builds small and fast.
Here's what this looks like in the actual pipeline:
The top-level workflow calls out to a file called container.sh:
# container.sh
buildah login -u $DO_REGISTRY_SECRET -p $DO_REGISTRY_SECRET registry.digitalocean.com
/bin/bash ./container_builds/node_package/build.sh $BUILD_PACKAGE
buildah push $BUILD_PACKAGE:latest registry.digitalocean.com/nerve/$BUILD_PACKAGE:$GITHUB_SHA
./container_builds/node_package/build.sh looks like this:
# build.sh
./container_builds/node_package/setup-registry.sh
container=$(buildah from --network=host node:20-alpine)
buildah run $container -- mkdir -p /src/nerve
buildah config --workingdir /src/nerve $container
buildah copy $container mockApiFixtures /src/nerve/mockApiFixtures
buildah run $container -- yarn init -yp
buildah run $container -- yarn set version 3.6.3
buildah copy $container $HOME/.yarn/berry/cache .yarn/global/cache
buildah copy $container 'yarn.lock' 'yarn.lock'
buildah run $container -- yarn config set npmRegistryServer 'http://127.0.0.1:4873'
buildah run $container -- yarn config set unsafeHttpWhitelist '127.0.0.1'
buildah run $container -- yarn config set enableGlobalCache false
buildah run $container -- yarn config set cacheFolder '.yarn/local'
buildah run $container -- yarn config set globalFolder '.yarn/global'
buildah run $container -- yarn add $1@999.999.999
buildah run $container -- yarn install
buildah run $container -- rm -rf '.yarn/global'
buildah config --entrypoint "/usr/bin/env yarn run $1" $container
buildah commit $container $1:latest
./container_builds/node_package/teardown-registry.shFinally, here's what setup-registry.sh and teardown-registry.sh look like:
# setup-registry.sh
# clean up from last run. if the dir doesn't exist, don't fail.
# recreate the dir no matter what.
#
# notice that we're deleting storage/ here - this is intentional.
# we want to republish every package every time.
rm -rf ~/.config/verdaccio
mkdir -p ~/.config/verdaccio
cp container_builds/node_package/config.yaml ~/.config/verdaccio/config.yaml
yarn run verdaccio 1>/dev/null 2>&1 &
yarn workspaces foreach --no-private --parallel npm publish
# teardown-registry.sh
# on CICD we don't really care if this process sticks around; everything
# runs in containers anyway so it's all ephemeral
#
# pkill -fi verdaccio
(The truth comes out...teardown-registry.sh is empty!)
This all runs in eighty to ninety seconds.
Caveats and Alternatives
buildah requires a couple of syscalls that Docker locks down by default via seccomp. Running buildah in a container means I need to punch a hole in the seccomp profile that the container is using (you'll see in the complete workflow below that I'm currently disabling seccomp completely; I gotta go back and instead just allow access to the specific syscalls that buildah needs.)
As a rule I don't like to mess around with secure defaults, but in this case I'm not sure there's any reasonable way to avoid it.
The complete workflow
Below is our CI workflow, in its entirety. You'll notice it calls out to the scripts that we listed in the earlier parts of the post!
# ci.yml
name: CI
on:
push: # Triggered on push events
branches:
- prod
pull_request:
branches:
- prod
env:
DO_REGISTRY_SECRET: ${{ secrets.DO_REGISTRY_SECRET }}
DO_SPACES_SECRET: ${{ secrets.DO_SPACES_SECRET }}
CLOUDFLARE_API_TOKEN: ${{ secrets.CLOUDFLARE_API_TOKEN }}
jobs:
build:
runs-on: ubuntu-latest
container:
image: "node:16-alpine"
steps:
- name: Install Git
run: apk add --no-cache git
- name: Checkout repository
uses: actions/checkout@v2
with:
# we have to scan backwards in the git history to
# find an available hydrator build
fetch-depth: "30"
- name: Init job
run: chmod +x ./.github/init-job.sh && ./.github/init-job.sh
- name: "build"
run: |
yarn tsc -b .
node hydrator/bin/bootstrap.js --force stash $GITHUB_SHA
test:
runs-on: ubuntu-latest
container: "node:16-alpine"
needs: build
steps:
- name: Install Git
run: apk add --no-cache git
- name: Checkout repository
uses: actions/checkout@v2
- name: Init job
run: chmod +x ./.github/init-job.sh && ./.github/init-job.sh
- name: test
run: yarn jasmine
cycles:
runs-on: ubuntu-latest
container: "node:16-alpine"
needs: build
steps:
- name: Install Git
run: apk add --no-cache git
- name: Checkout repository
uses: actions/checkout@v2
- name: Init job
run: chmod +x ./.github/init-job.sh && ./.github/init-job.sh
- name: test for cycles
run: ./ci/cycles.sh
container-backend:
runs-on: ubuntu-latest
container:
image: "mprast/node-with-buildah:16-alpine"
options:
--privileged
--security-opt seccomp=unconfined
--security-opt no-new-privileges
needs: build
env:
STORAGE_DRIVER: "vfs"
BUILDAH_FORMAT: "docker"
BUILD_PACKAGE: "nerve-backend"
steps:
- name: Install Git
run: apk add --no-cache git
- name: Checkout repository
uses: actions/checkout@v2
- name: Init job
run: chmod +x ./.github/init-job.sh && ./.github/init-job.sh
- name: container
run: chmod +x ./.github/container.sh && ./.github/container.sh
container-engine:
runs-on: ubuntu-latest
container:
image: "mprast/node-with-buildah:16-alpine"
# need to set these in order for buildah to work in the container
options:
--privileged
--security-opt seccomp=unconfined
--security-opt no-new-privileges
needs: build
env:
STORAGE_DRIVER: "vfs"
BUILDAH_FORMAT: "docker"
BUILD_PACKAGE: "nerve-engine"
steps:
- name: Install Git
run: apk add --no-cache git
- name: Checkout repository
uses: actions/checkout@v2
- name: Init job
run: chmod +x ./.github/init-job.sh && ./.github/init-job.sh
- name: container
run: chmod +x ./.github/container.sh && ./.github/container.sh
bundle-prod:
runs-on: ubuntu-latest
container: "node:16-alpine"
needs: build
env:
FOR_PLAYGROUND: "false"
FRONTEND_ENV: "prod"
steps:
- name: Install Git
run: apk add --no-cache git
- name: Checkout repository
uses: actions/checkout@v2
- name: Init job
run: chmod +x ./.github/init-job.sh && ./.github/init-job.sh
- name: bundle
run: chmod +x ./.github/bundle.sh && ./.github/bundle.sh
bundle-playground:
runs-on: ubuntu-latest
container: "node:16-alpine"
needs: build
env:
FOR_PLAYGROUND: "true"
FRONTEND_ENV: "demo"
steps:
- name: Install Git
run: apk add --no-cache git
- name: Checkout repository
uses: actions/checkout@v2
- name: Init job
run: chmod +x ./.github/init-job.sh && ./.github/init-job.sh
- name: bundle
run: chmod +x ./.github/bundle.sh && ./.github/bundle.sh
cleanup-failed-build:
runs-on: ubuntu-latest
container: "mprast/node-with-doctl:16-alpine"
needs: [test, cycles, container-engine, container-backend, bundle-prod, bundle-playground]
if: "failure()"
steps:
- name: Install Git
run: apk add --no-cache git
- name: Checkout repository
uses: actions/checkout@v2
- name: Init job
run: chmod +x ./.github/init-job.sh && ./.github/init-job.sh
- name: cleanup
run: chmod +x ./.github/cleanup.sh && ./.github/cleanup.shFuture Work
Move to tsc 7
This one's pretty self-explanatory. As soon as I can upgrade to the Go-based tsc I can get rid of a lot of the build-caching machinery, which is a pretty big win simplicity-wise. That said, to do that I'll need to make the leap from Typescript 4.9 to Typescript 7, which will take a while (kids, this is why you shouldn't fall behind on upgrades, even if you don't feel like you need any features in the new version. Oh well - the best time to upgrade was a couple years ago, the second best time is now)
Cache or check in .pnp.cjs
Checking in .pnp.cjs or caching it via hydrator means yarn won't have to regenerate it on every install. This will only save a few seconds each time, but it's basically free - I just have to get around to doing it.
Rewrite shell scripts in Typescript
This one isn't as much about performance as it is about keeping things accessible to other devs and avoiding "special" code (i.e. bash scripts.) The idea is not necessarily to reimplement the entire build pipeline, but instead to use something like zx or dax to make it a little easier to construct the necessary shell calls and do control flow and error handling. This also lets us use familiar patterns and maybe even pull out some shared functionality into a standard library we can use across various infrastructure projects.
That said - the build process is simple enough right now that porting to Typescript will probably not move the needle in the near-term, but it's easy to do and a good opportunity to set the habit.
Implement yarn cache pruning
I mentioned earlier that the way we update our yarn cache in DO Spaces is purely additive. To keep the package cache from growing forever, I'm planning to simply add a new job that periodically does a yarn install from scratch and uploads the result as the build for the commit that the dev branch is currently at. However, this is one of those pieces of tech debt that mainly serves to keep things from tipping over, and I don't think the yarn cache size will hit a crisis point for quite a while, so I probably won't get around to implementing this in the near future.
More tests
I mentioned before I'm going to be doing a bunch of work on expanding test coverage. As part of this I'll be writing more Intra-Process Integration Tests to cover as much ground as I can - a big part of this will be figuring out how well the pattern generalizes to different parts of the app.
Performance tests
Being a dev tool, it's important that Nerve is fast - both for the sake of a better DX and because the Nerve engine affects the performance of our own users' code. The next big work item for the build pipeline is to add automated performance testing that will fail the build if a metric crosses a certain threshold. There are a number of things that will be useful to measure here - fast query execution is clearly the most important, but things like TTI and API latency for the webapp are also worth optimizing where possible. And - since fast infrastructure is a priority for us - we'll track some internal metrics around things like container size, startup time for the backend/agent, and - naturally - build times themselves!
Nerve is still small enough that it doesn't really make sense to track everything right away; we will probably start with query execution time and then add other metrics on as needed. When our performance measurement capabilities are more mature I'll write another blog post about it!